Why you’ll love Versapay:
-
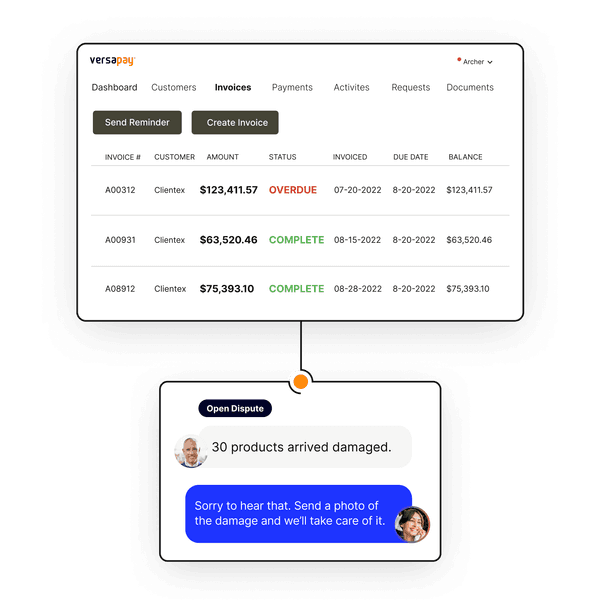
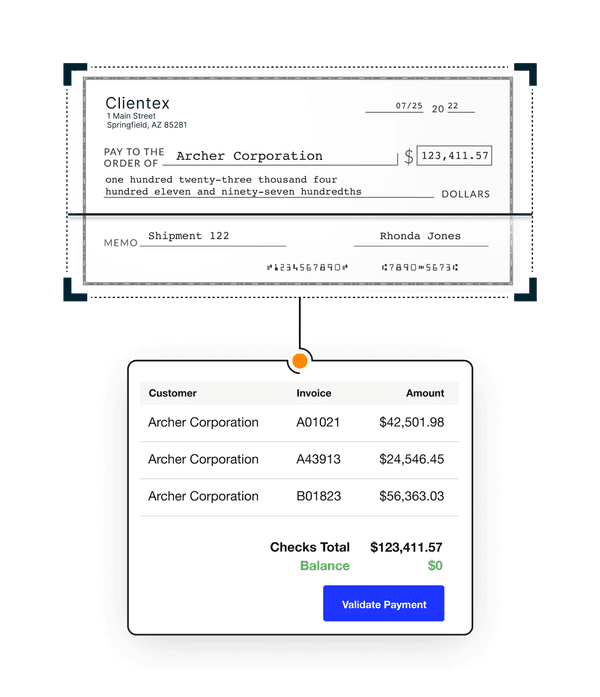
Effortless invoicing, collections, and cash application
-
Real-time visibility across customers, divisions, and countries
-
Integrated collaboration
-
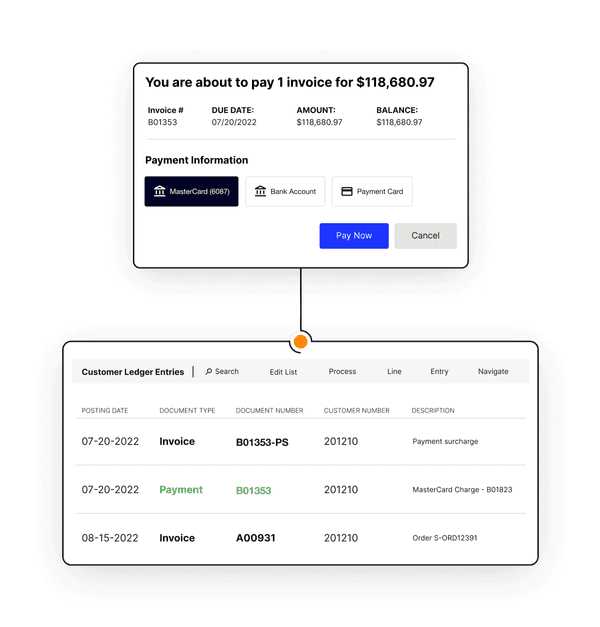
Straight-through payment processing
-
Actionable insights
-
ERP integrations